As you probably know, Microsoft made a huge step up with MS SQL 2019 Big Data Cluster (BDC) what converts old OLTP based SQL server to a new shinny data hub with unlimited possibilities. One of the new features is to query directly from an S3 AWS bucket using T-SQL. Sounds good right? To get this done we need – S3 bucket with files (I’ll be using parquet files) and running BDC. Tools I’ll be using – Azure Data Studio and CMD. Let’s get started!
First, we need to mount the S3 bucket to BDC. Run the code below in CMD:
set MOUNT_CREDENTIALS=fs.s3a.access.key=<access key>, fs.s3a.secret.key=<secret key> azdata login -e https://<BDC ip address>:30080/ azdata bdc hdfs mount create --remote-uri s3a://<s3 bucket> --mount-path /<BDC path>
Let’s get through these commands. To set credentials, replace <access key> to your S3 bucket access key and <secret key> accordingly to secret key:
Now login to BDC. Replace IP address to your BDC IP and submit login details:
And the last step is to mount S3 bucket to BDC. Replace <s3 bucket> to your S3 bucket/folder and <BDC path> – the path to hook up in your HDFS:
To check the status of your mount, you may run the command below:
azdata bdc hdfs mount status

The state Ready means the bucket is mounted and ready to use.
Now, let’s switch to the Azure Data Studio (ADS). To verify the mounted S3 bucket is available, we may check under HDFS folder after connected to BDC:
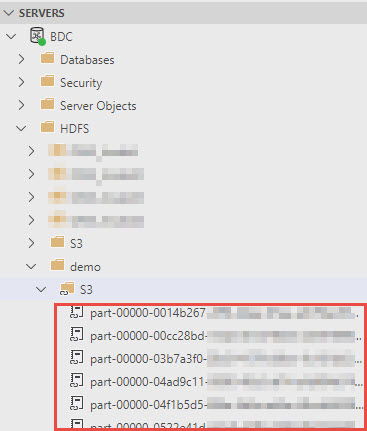
The next step is to create an external file format, external data source and external table to be able to finally query the data. To create the format execute a script:
CREATE EXTERNAL FILE FORMAT s3_parquet_format
WITH (
FORMAT_TYPE = PARQUET,
DATA_COMPRESSION = 'org.apache.hadoop.io.compress.SnappyCodec'
);
I set the name of the format to s3_parquet_format and since the files in the S3 bucket are parquet with snappy compression – format type is parquet and data compression is org.apache.hadoop.io.compress.SnappyCodec accordingly. Here is the list of all available formats.
To create an external data source:
CREATE EXTERNAL DATA SOURCE SqlStoragePool
WITH (LOCATION = 'sqlhdfs://controller-svc/default');
And the very last step is to create an external table. To do this, need to know the schema of parquet files:
CREATE EXTERNAL TABLE [S3_demo_data]
(
"column1" bigint,
"column2" int,
"column3" int,
"column4" int,
"column5" int,
"column6" int,
"column7" int,
"column8" int,
"column9" varchar(3),
"column10" varchar(3),
"column11" int,
"column12" varchar(3),
"column13" varchar(3),
"column14" varchar(3),
"column15" varchar(3),
"column16" varchar(10),
"column17" int,
<...>
"column_n" varchar(3)
)
WITH
(
DATA_SOURCE = SqlStoragePool,
LOCATION = '/demo/S3',
FILE_FORMAT = s3_parquet_format
)
GO
Where location is the S3 bucket mount on BDC and the file format s3_parquet_format we’ve created recently.
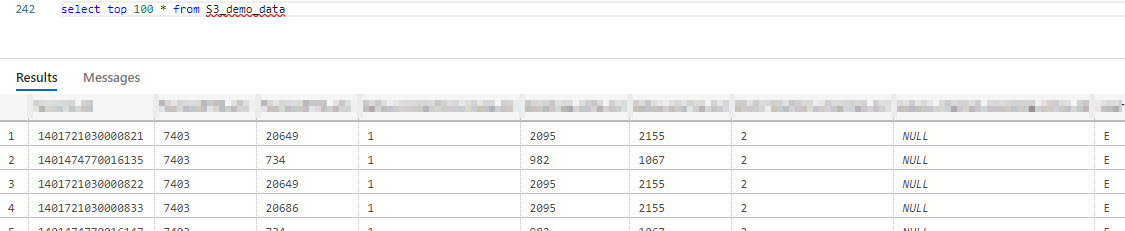
Finally, let’s try to query the data:
{kind=link}
{kind=link}
{kind=link}
Hope this tip gonna be helpful. Thanks for reading!